pip installieren BeautifulSoup4
Um zu überprüfen, ob die Installation erfolgreich war, aktivieren Sie die interaktive Python-Shell und importieren Sie BeautifulSoup. Wenn kein Fehler angezeigt wird, bedeutet dies, dass alles gut gelaufen ist. Wenn Sie nicht wissen, wie das geht, geben Sie die folgenden Befehle in Ihr Terminal ein.
$pythonPython 3.5.2 (Standard, 14.09.2017, 22:51:06)
[GCC 5.4.0 20160609] unter Linux
Geben Sie "Hilfe", "Copyright", "Credits" oder "Lizenz" ein, um weitere Informationen zu erhalten.
>>> bs4 importieren
Um mit der BeautifulSoup-Bibliothek zu arbeiten, müssen Sie html . eingeben. Wenn Sie mit echten Websites arbeiten, können Sie den HTML-Code einer Webseite mithilfe der Anforderungsbibliothek abrufen. Die Installation und Verwendung der Anforderungsbibliothek würde den Rahmen dieses Artikels sprengen, Sie können sich jedoch in der Dokumentation zurechtfinden, die ziemlich einfach zu verwenden ist. Für diesen Artikel verwenden wir einfach HTML in einem Python-String, den wir aufrufen würden html.
html = """[E-Mail geschützt]
pparkerworks.com
"""
Um beautifulsoup zu verwenden, importieren wir es mit dem folgenden Code in den Code:
aus bs4 importieren BeautifulSoupDies würde BeautifulSoup in unseren Namespace einführen und wir können es beim Parsen unseres Strings verwenden use.
Suppe = SchöneSoup(html, "lxml")Jetzt, Suppe ist ein BeautifulSoup-Objekt vom Typ bs4.BeautifulSoup und wir können alle BeautifulSoup-Operationen auf der SuppeVariable.
Werfen wir einen Blick auf einige Dinge, die wir jetzt mit BeautifulSoup machen können.
DAS HÄSSLICHE, SCHÖNE MACHEN
Wenn BeautifulSoup HTML analysiert, ist es normalerweise nicht das beste Format. Der Abstand ist ziemlich schrecklich. Die Tags sind schwer zu finden. Hier ist ein Bild, um zu zeigen, wie sie aussehen würden, wenn Sie sie drucken können Suppe:
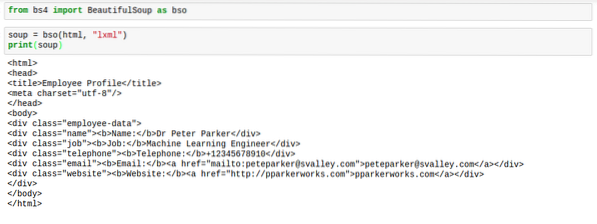
Dafür gibt es jedoch eine Lösung. Die Lösung gibt dem HTML den perfekten Abstand, damit die Dinge gut aussehen. Diese Lösung heißt zu Recht „verschönern“.
Zugegeben, Sie können diese Funktion die meiste Zeit möglicherweise nicht nutzen; Es gibt jedoch Zeiten, in denen Sie möglicherweise keinen Zugriff auf das Elementprüfungstool eines Webbrowsers haben. In Zeiten begrenzter Ressourcen würden Sie die Prettify-Methode sehr nützlich finden.
So verwenden Sie es:
Suppe.verschönern()Das Markup würde wie in der Abbildung unten richtig verteilt aussehen:
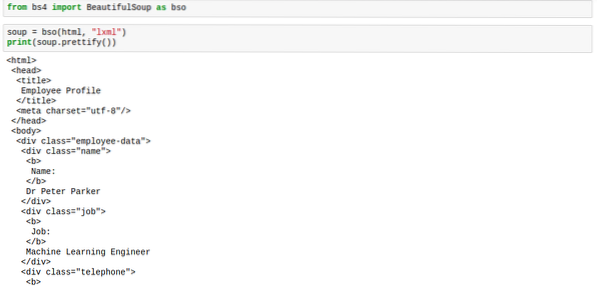
Wenn Sie die Verschönerungsmethode auf die Suppe anwenden, ist das Ergebnis kein Typ mehr bs4.SchöneSuppe. Das Ergebnis ist jetzt 'unicode'. Dies bedeutet, dass Sie keine anderen BeautifulSoup-Methoden darauf anwenden können, die Suppe selbst ist jedoch nicht betroffen, sodass wir in Sicherheit sind.
UNSERE LIEBLINGSTAGS FINDEN
HTML besteht aus Tags. Es speichert alle seine Daten darin, und inmitten all dieses Durcheinanders liegen die Daten, die wir brauchen. Im Grunde bedeutet das, wenn wir die richtigen Tags finden, können wir bekommen, was wir brauchen.
Wie finden wir die richtigen Tags? Wir verwenden die Methoden find und find_all von BeautifulSoup.
So funktionieren sie:
Das finden Methode sucht nach dem ersten Tag mit dem benötigten Namen und gibt ein Objekt vom Typ bs4 zurück.Element.Etikett.
Das finde alle -Methode hingegen sucht nach allen Tags mit dem benötigten Tag-Namen und gibt diese als Liste vom Typ bs4 zurück.Element.Ergebnismenge. Alle Elemente in der Liste sind vom Typ bs4.Element.Tag, damit wir die Liste indizieren und unsere schöne Suppen-Erkundung fortsetzen können.
Lass uns etwas Code sehen. Lassen Sie uns alle div-Tags finden:
Suppe.find(“div“)Wir würden folgendes Ergebnis erhalten:
Wenn Sie die HTML-Variable überprüfen, werden Sie feststellen, dass dies das erste div-Tag ist.
Suppe.find_all(“div“)Wir würden folgendes Ergebnis erhalten:
[[E-Mail geschützt]
pparkerworks.com
Es gibt eine Liste zurück. Wenn Sie beispielsweise das dritte div-Tag wünschen, führen Sie den folgenden Code aus:
Suppe.find_all(“div“)[2]Es würde folgendes zurückgeben:
FINDEN SIE DIE ATTRIBUTE UNSERER LIEBLINGSTAGS
Nachdem wir nun gesehen haben, wie wir unsere Lieblings-Tags erhalten, wie wäre es mit deren Attributen?
Sie denken jetzt vielleicht: „Wofür brauchen wir Attribute??“. Nun, oft sind die meisten Daten, die wir benötigen, E-Mail-Adressen und Websites. Diese Art von Daten wird normalerweise in Webseiten mit Hyperlinks versehen, wobei die Links im Attribut „href“ enthalten sind.
Wenn wir das benötigte Tag mit den Methoden find oder find_all extrahiert haben, können wir Attribute durch Anwenden erhalten attrs. Dies würde ein Wörterbuch des Attributs und seines Wertes zurückgeben.
Um beispielsweise das E-Mail-Attribut zu erhalten, erhalten wir das Tags, die die benötigten Informationen umgeben, und gehen Sie wie folgt vor.
Suppe.find_all(“a“)[0].attrsWas folgendes Ergebnis liefern würde:
'href': 'mailto:[email protected]'Gleiches gilt für das Website-Attribut.
Suppe.find_all(“a“)[1].attrsWas folgendes Ergebnis liefern würde:
'href': 'http://pparkerworks.com'Die zurückgegebenen Werte sind Wörterbücher und die normale Wörterbuchsyntax kann angewendet werden, um die Schlüssel und Werte zu erhalten.
LASSEN SIE UNS DIE ELTERN UND KINDER SEHEN
Überall sind Tags. Manchmal möchten wir wissen, was die Child-Tags sind und was das Parent-Tag ist.
Wenn Sie noch nicht wissen, was ein Parent- und Child-Tag ist, sollte diese kurze Erklärung genügen: Ein Parent-Tag ist das unmittelbare äußere Tag und ein Kind ist das unmittelbare innere Tag des betreffenden Tags.
Wenn Sie sich unseren HTML-Code ansehen, ist das body-Tag das übergeordnete Tag aller div-Tags. Außerdem sind das Fett-Tag und das Anchor-Tag die Kinder der div-Tags, da nicht alle div-Tags Anker-Tags besitzen.
So können wir auf das übergeordnete Tag zugreifen, indem wir das aufrufen findEltern Methode.
Suppe.find("div").findParent()Dies würde das gesamte Body-Tag zurückgeben:
[E-Mail geschützt]
pparkerworks.com
Um das Kinder-Tag des vierten div-Tags zu erhalten, rufen wir die findKinder Methode:
Suppe.find_all("div")[4].findKinder()Es gibt Folgendes zurück:
[Webseite:, pparkerworks.com]WAS IST FÜR UNS DAVON?
Beim Durchsuchen von Webseiten sehen wir nicht überall Tags auf dem Bildschirm. Wir sehen nur den Inhalt der verschiedenen Tags. Was ist, wenn wir den Inhalt eines Tags wollen, ohne dass all die spitzen Klammern das Leben unangenehm machen?? Das ist nicht schwer, wir rufen nur an get_text -Methode auf das Tag der Wahl und wir erhalten den Text im Tag und wenn das Tag andere Tags enthält, erhält es auch deren Textwerte.
Hier ist ein Beispiel:
Suppe.find("Körper").get_text()Dies gibt alle Textwerte im body-Tag zurück:
Name: Dr. Peter ParkerJob:Ingenieur für maschinelles Lernen
Telefon:+12345678910
E-Mail:[E-Mail geschützt]
Website:pparkerworks.com
FAZIT
Das haben wir für diesen Artikel. Es gibt jedoch noch andere interessante Dinge, die man mit beautifulsuppe machen kann. Sie können entweder die Dokumentation lesen oder verwenden dir(SchöneSuppe) auf der interaktiven Shell, um die Liste der Operationen anzuzeigen, die an einem BeautifulSoup-Objekt ausgeführt werden können. Das ist alles von mir heute, bis ich wieder schreibe.


