Um das Konzept der Volltextsuche zu verstehen, muss man sich das Wissen über Mustersuche über das Schlüsselwort LIKE aneignen. Nehmen wir also eine Tabelle 'person' in der Datenbank 'test' mit den folgenden Datensätzen darin an.
>> AUSWÄHLEN * VON Person;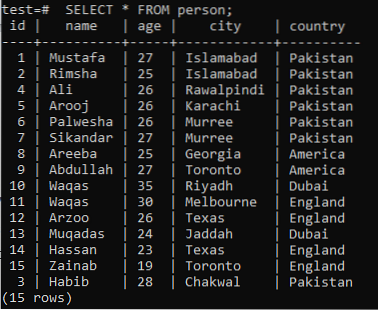
Nehmen wir an, Sie möchten die Datensätze dieser Tabelle abrufen, deren Spaltenname ein Zeichen i in einem ihrer Werte enthält. Versuchen Sie die folgende SELECT-Abfrage, während Sie die LIKE-Klausel in der Befehlsshell verwenden. Aus der Ausgabe unten können Sie sehen, dass wir nur 5 Datensätze für dieses bestimmte Zeichen 'i' in der Spalte 'Name' haben.
>> SELECT * FROM Person WHERE Name LIKE '%i%';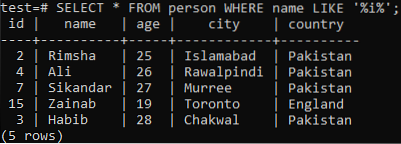
Nutzung des Fernsehsektors:
Manchmal ist es nutzlos, das LIKE-Schlüsselwort zu verwenden, um eine schnelle Mustersuche durchzuführen, obwohl das Wort vorhanden ist. Vielleicht erwägen Sie die Verwendung von Standardausdrücken, und obwohl dies eine praktikable Alternative ist, sind reguläre Ausdrücke sowohl stark als auch träge. Einen prozeduralen Vektor für ganze Wörter in einem Text zu haben, eine volkssprachliche Beschreibung dieser Wörter, ist eine viel effizientere Möglichkeit, dieses Problem anzugehen. Um darauf zu reagieren, wurde das Konzept der Volltextsuche und der Datentyp tsvector entwickelt. Es gibt zwei Methoden in PostgreSQL, die genau das tun, was wir wollen:
- An_tvsektor: Wird verwendet, um eine Liste von Token zu erstellen (ts bedeutet für "Textsuche").
- To_tsquery: Wird verwendet, um den Vektor nach Vorkommen bestimmter Begriffe oder Phrasen zu durchsuchen.
Beispiel 01:
Beginnen wir mit einer einfachen Illustration zum Erstellen eines Vektors. Angenommen, Sie möchten einen Vektor für die Zeichenfolge erstellen: „Manche Leute haben durch richtiges Bürsten lockiges braunes Haar.”. Sie müssen also eine to_tvsector()-Funktion zusammen mit diesem Satz in die Klammern einer SELECT-Abfrage schreiben, wie unten angehängt. Aus der Ausgabe unten können Sie sehen, dass sie für jedes Token einen Vektor von Referenzen (Dateipositionen) liefern würde und auch dort, wo Begriffe mit wenig Kontext, wie Artikel (der) und Konjunktionen (und, oder), absichtlich ignoriert werden.
>> SELECT to_tsvector('Einige Leute haben durch richtiges Bürsten lockige braune Haare');
Beispiel 02:
Angenommen, Sie haben zwei Dokumente mit einigen Daten in beiden. Um diese Daten zu speichern, verwenden wir jetzt ein echtes Beispiel für die Generierung von Token. Angenommen, Sie haben mit der folgenden CREATE TABLE-Abfrage eine Tabelle 'Data' in Ihrer Datenbank 'test' mit einigen Spalten erstellt. Vergessen Sie nicht, darin eine Spalte vom Typ TVSECTOR mit dem Namen 'token' zu erstellen. In der Ausgabe unten können Sie sich die erstellte Tabelle ansehen.
>> CREATE TABLE Data (Id SERIAL PRIMARY KEY, Info-TEXT, Token TSVECTOR);
Nun müssen wir die Gesamtdaten der beiden Dokumente in dieser Tabelle hinzufügen. Versuchen Sie dazu den folgenden INSERT-Befehl in Ihrer Befehlszeilen-Shell. Schließlich wurden die Datensätze aus beiden Dokumenten erfolgreich in die Tabelle 'Daten' hinzugefügt.
>> INSERT INTO Data (info) VALUES ('Zwei Fehler können niemals einen richtig machen.'), ('Er ist derjenige, der Fußball spielen kann.'), ('Kann ich dazu beitragen??'), ('Der Schmerz in einem kann nicht verstanden werden'), ('Bring Pfirsich in dein Leben);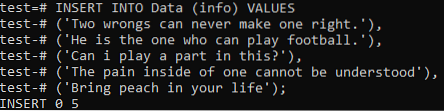
Jetzt müssen Sie die Token-Spalte beider Dokumente mit ihrem spezifischen Vektor kolonisieren. Letztendlich füllt eine einfache UPDATE-Abfrage die Token-Spalte mit ihrem entsprechenden Vektor für jede Datei fill. Sie müssen also die unten angegebene Abfrage in der Befehlsshell ausführen, um dies zu tun. Die Ausgabe zeigt, dass das Update endlich durchgeführt wurde.
>> UPDATE Daten f1 SET Token = to_tsvector(f1.info) FROM Daten f2;
Nun, da wir alles an Ort und Stelle haben, kehren wir zu unserer Illustration von „kann man“ mit einem Scan zurück. To_tsquery mit dem AND-Operator, wie bereits erwähnt, macht keinen Unterschied zwischen den Speicherorten der Dateien in den Dateien, wie in der unten angegebenen Ausgabe gezeigt.
>> SELECT Id, info FROM Data WHERE Token @@ to_tsquery('can & one');
Beispiel 04:
Um Wörter zu finden, die „nebeneinander“ sind, versuchen wir dieselbe Abfrage mit dem '<->' Operator. Die Änderung wird in der Ausgabe unten angezeigt.
>> SELECT Id, info FROM Data WHERE Token @@ to_tsquery('can <-> einer');
Hier ist ein Beispiel für kein unmittelbares Wort neben einem anderen.
>> SELECT Id, info FROM Data WHERE Token @@ to_tsquery('one <-> Schmerzen');
Beispiel 05:
Wir finden die Wörter, die nicht unmittelbar nebeneinander stehen, indem wir eine Zahl im Entfernungsoperator verwenden, um die Entfernung zu referenzieren. Die Nähe zwischen 'bring' und 'life' beträgt 4 Wörter außer dem angezeigten Bild.
>> SELECT * FROM Data WHERE Token @@ to_tsquery('bring <4> Leben');
Um die Nähe zwischen den Wörtern für fast 5 Wörter zu überprüfen, ist unten angehängt.
>> SELECT * FROM Data WHERE Token @@ to_tsquery('falsch <5> Recht');
Fazit:
Schließlich haben Sie alle einfachen und komplizierten Beispiele für die Volltextsuche mit den Operatoren und Funktionen To_tvsector und to_tsquery durchgeführt.


