Funktionsdefinition
Bevor Sie die Lesefunktion in Ihrem Code definieren, müssen Sie einige erforderliche Pakete einfügen.
#einschließenSo definieren Sie die POSIX-Lesefunktion:
>> ssize_t pread(int fildes, void *buf, size_t nbyte, off_t offset);>> ssize_t read(int fd, void *buf, size_t nbytes);
Drei Parameterargumente können dem read-Methodenaufruf entnommen werden:
int fd: Der Dateideskriptor der Datei, aus der die Informationen gelesen werden sollen. Wir könnten entweder einen Dateideskriptor verwenden, der über einen offenen Systemaufruf abgerufen wurde, oder wir könnten einfach 0, 1 oder 2 verwenden, die sich auf eine typische Eingabe, eine reguläre Ausgabe bzw. einen regulären Fehler beziehen.
Leere *buf: Der Puffer oder das Zeichenarray, in dem die gelesenen Daten gespeichert und aufbewahrt werden sollen.
Größe_t nbyte: Die Anzahl der Bytes, die vor dem Abschneiden aus dem Dokument gelesen werden mussten. Alle Informationen können im Puffer gespeichert werden, wenn die zu lesenden Informationen kürzer als nByte sind.
Beschreibung
Die Methode read() versucht, 'nbyte' Bytes in den Puffercache zu lesen, auf den 'buf' verweist, entweder aus der Datei, die mit dem offenen Dokumentdeskriptor 'Fildes' oder 'fd' verbunden ist. Es definiert nicht die Art mehrerer gleichzeitiger Lesevorgänge auf demselben Datenstrom, FIFO oder Terminaleinheit terminal.
Bei Dokumenten, die das Lesen ermöglichen, beginnt der Lesevorgang am Offset des Dokuments und der Offset wird um die Anzahl der gelesenen Bytes erhöht. Wenn der Dokument-Offset am Rand der Datei oder darüber hinaus liegt, werden keine Bytes gelesen und read() liefert keine.
Wenn der Zähler 0 ist, erkennt read() die unten genannten Fehler. Wenn keine Fehler vorliegen oder read() nicht mit Errors berücksichtigt wird, liefert ein read() null mit einem Zählerstand von 0 und hat daher keine weiteren Auswirkungen.
Wenn die Anzahl höher als SSIZE_MAX ist, gemäß POSIX.1, dann wird das Ergebnis durch die Implementierung bestimmt.
Rückgabewert
Die Zahl der Bytes 'read' und 'pred', die bei Erreichen zurückgesetzt werden, muss eine nicht negative ganze Zahl sein, während Null auf das Ende der Datei zeigt. Die Position des Dokuments wird um diese Nummer weitergeschaltet, oder um einen Fehler anzuzeigen, geben die Methoden -1 zurück und weisen 'errno' zu. Wenn diese Zahl kleiner ist als die angeforderte Anzahl von Bytes, handelt es sich nicht um ein Fehlerbyte. Es könnte möglich sein, dass vorerst weniger Bytes verfügbar sind.
Fehler
Die Vorlese- und Lesefunktion schlägt fehl, wenn diese Fehler auftreten:
WIEDER:
Der Dokument- oder Dateideskriptor 'fd' gehört zu einer Nicht-Socket-Datei, die als nicht-blockierend (O NONBLOCK) gekennzeichnet wurde und das Lesen blockiert.
EWOULDBLOCK:
Der Deskriptor 'fd' gehört zu einem Socket, der als nicht-blockierend (O_NONBLOCK) gekennzeichnet wurde und das Lesen blockiert.
EBADF:
Das 'fd' ist möglicherweise kein brauchbarer Deskriptor oder es ist möglicherweise nicht zum Lesen geöffnet.
AUSFALL:
Dies passiert, wenn sich Ihr 'buf' außerhalb Ihres erreichbaren Adressraums befindet.
EINTR:
Vor dem Auslesen der Informationsdaten kann der Anruf durch ein Signal unterbrochen worden sein.
EINVAL:
Dieser Fehler tritt auf, wenn Ihr 'fd'-Deskriptor an einem Objekt beteiligt ist, das nicht zum Lesen geeignet ist, oder das Dokument mit dem O_DIRECT-Flag gelöst wurde und die eine oder andere Adresse in 'buf' angegeben ist, der Wert in 'count ', oder der Dokumentenversatz ist nicht richtig zugeordnet.
EINVAL:
Der Deskriptor 'fd' wurde möglicherweise mit einem Aufruf von timerfd_create(2) gebildet, und der Puffer mit der falschen Größe wurde an read übergeben.
EIO:
Es ist ein Eingabe-/Ausgabefehler. Es tritt auf, wenn die Hintergrundprozessgruppe versucht, von ihrem Regulierungsterminal zu lesen, und der eine oder andere SIGTTIN übersieht oder blockiert oder ihre Prozessgruppe hinterlässt. Ein weiterer Grund für diesen Fehler kann ein Low-Level-Ein-/Ausgabefehler beim Lesen von einer Festplatte oder einem Band sein. Eine weitere mögliche Ursache für EIO bei vernetzten Datendateien ist die Entfernung der beratenden Sperre für den Dateideskriptor und das Versagen dieser Sperre.
EISDIR:
Der Dateideskriptor 'fd' gehört zu einem Verzeichnis.
Anmerkungen:
Es können auch viele andere Fehler auftreten, abhängig von dem Objekt, das mit dem Deskriptor 'fd' verknüpft ist. Sowohl size_t- als auch ssize_t-Formen sind unmarkierte und markierte numerische Datentypen, die von POSIX definiert werden.1. Unter Linux können höchstens 0x7ffff000 (2.147.479.552) Bytes durch die Lesefunktion (und entsprechende Systemaufrufe) übertragen werden, wobei die Anzahl der ursprünglich übertragenen Bytes zurückgegeben wird (auf 32-Bit- und 64-Bit-Plattformen). Bei NFS-Dateisystemen wird der Zeitstempel nur im ersten Moment durch das Lesen winziger Informationsströme geändert, nachfolgende Aufrufe würden dies nicht tun. Es wird durch das Caching von clientseitigen Attributen ausgelöst, da, obwohl nicht alle NFS-Clients die Aktualisierung auf den Server über st_atime (letzte Dateizugriffszeit) beenden und clientseitige Reads, die aus dem Puffer des Clients ausgeführt werden, keine Änderungen an st- atime auf dem Server, da keine serverseitigen Messwerte verfügbar sind. Durch das Entfernen des clientseitigen Attribut-Caching kann auf UNIX-Metadaten zugegriffen werden, dies würde jedoch die Serverlast erheblich erhöhen und in den meisten Fällen die Produktivität beeinträchtigen.
Beispiel 01:
Hier ist ein C-Programm, um den Lesefunktionsaufruf auf dem Linux-System zu demonstrieren. Schreiben Sie den unten stehenden Befehl so, wie er in einer neuen Datei ist. Bibliotheken hinzufügen und in der Hauptfunktion einen Deskriptor und eine Größe initialisieren. Der Deskriptor öffnet die Datei und die Größe wird zum Lesen der Dateidaten verwendet.
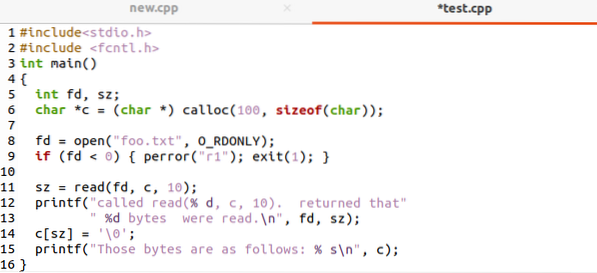
Die Ausgabe für den obigen Code wäre wie im folgenden Bild gezeigt.

Beispiel 02:
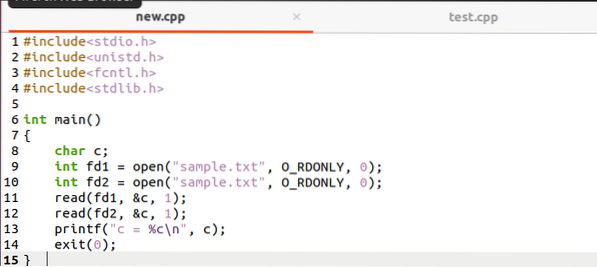
Ein weiteres Beispiel zur Veranschaulichung der Funktionsweise der Lesefunktion ist unten aufgeführt.
Erstellen Sie eine weitere Datei und schreiben Sie den Code unten so auf, wie er darin ist. Hier sind zwei Deskriptoren, fd1 & fd2, die beide ihren eigenen Zugriff auf offene Tabellendateien haben. Also für foobar.txt hat jeder Deskriptor seinen Dateispeicherort. Das allererste Byte von foobar.txt wird aus fd2 übersetzt und das Ergebnis ist c = f, nicht c = o.
Fazit
Wir haben die POSIX-Lesefunktion in der C-Programmierung effizient gelesen. Hoffentlich bleiben keine Zweifel mehr.


