Eine Pivot-Tabelle ist ein leistungsstarkes Tool zum Schätzen, Kompilieren und Überprüfen von Daten, um Muster und Trends noch einfacher zu finden. Pivot-Tabellen können verwendet werden, um Daten in einem Dataset zu aggregieren, zu sortieren, anzuordnen, neu anzuordnen, zu gruppieren, zu summieren oder zu mitteln, um Datenassoziationen und Abhängigkeiten wirklich zu verstehen. Die Verwendung einer Pivot-Tabelle als Illustration ist der einfachste Weg, die Funktionsweise dieser Methode zu demonstrieren method. PostgreSQL 8.3 wurde vor einigen Jahren auf den Markt gebracht und eine neue Version namens 'Tischfunktion' wurde hinzugefügt. Tischfunktion ist eine Komponente, die mehrere Methoden enthält, die Tabellen liefern (d. h. mehrere Zeilen). Diese Modifikation kommt mit einer sehr coolen Auswahl an Funktionen. Die Kreuztabellenmethode, mit der Pivot-Tabellen erstellt werden, gehört dazu. Die Kreuztabellenmethode verwendet ein Textargument: einen SQL-Befehl, der Rohdaten im ersten Layout und eine Tabelle im nachfolgenden Layout zurückgibt.
Beispiel für eine Pivot-Tabelle ohne TableFunc:
Um mit der Arbeit am PostgreSQL-Pivoting mit dem 'tablefunc'-Modul zu beginnen, müssen Sie versuchen, eine Pivot-Tabelle ohne es zu erstellen. Öffnen wir also die PostgreSQL-Befehlszeilen-Shell und geben Sie die Parameterwerte für den erforderlichen Server, die Datenbank, die Portnummer, den Benutzernamen und das Passwort ein. Lassen Sie diese Parameter leer, wenn Sie die standardmäßig ausgewählten Parameter verwenden möchten.
Wir werden eine neue Tabelle namens 'Test' in der Datenbank 'test' mit einigen Feldern erstellen, wie unten gezeigt.
>> CREATE TABLE Test(Id int, name varchar(20), sal int, job varchar(20));
Nachdem Sie eine Tabelle erstellt haben, ist es an der Zeit, einige Werte in die Tabelle einzufügen, wie in der folgenden Abfrage gezeigt.
>> INSERT INTO Test (Id, name, sal, job) WERTE (11, 'Aqsa', 45000, 'Writer'), (11, 'Aqsa', 48000, 'Officer'), (11, 'Aqsa', 50000, 'Arzt'), (12, 'Raza', 40000, 'Beamter'), (11, 'Raza', 60000, 'Arzt'), (12, 'Raza', 67000, 'Beamter'), ( 13, 'Saeed', 85000, 'Schriftsteller'), (13, 'Saeed', 69000, 'Beamter'), (13, 'Saeed', 90000, 'Arzt');
Sie sehen, dass die relevanten Daten erfolgreich eingefügt wurden. Sie können sehen, dass diese Tabelle mehr als einen der gleichen Werte für ID, Name und Job enthält.
>> AUSWÄHLEN * VON der Eingabe;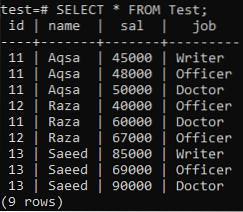
Lassen Sie uns eine Pivot-Tabelle erstellen, die den Datensatz der Tabelle 'Test' mit der folgenden Abfrage zusammenfasst. Der Befehl führt die gleichen Werte der Spalte "Id" und "Name" in einer Zeile zusammen, während die Summe der Spaltenwerte "Gehalt" für die gleichen Daten gemäß "Id" und "Name" verwendet wird. Es sagt auch, wie oft ein Wert in der bestimmten Wertemenge vorgekommen ist.
>> SELECT Id, name, sum(sal) sal, sum((job = 'Doctor')::int) Doctor, sum((job = 'Writer')::int) Writer, sum((job = 'Officer ')::int) "Offizier" FROM Test GROUP BY Id, Name;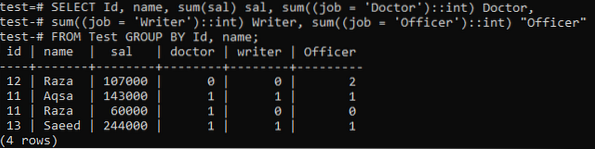
Beispiel für eine Pivot-Tabelle mit TableFunc:
Wir beginnen damit, unseren Hauptpunkt von einem realistischen Standpunkt aus zu erklären, und beschreiben dann die Erstellung der Pivot-Tabelle in Schritten, die wir mögen. Zuerst müssen Sie also drei Tabellen hinzufügen, um an einem Pivot zu arbeiten. Die erste Tabelle, die wir erstellen werden, ist 'Make-up', in der Informationen zu Makeup-Essentials gespeichert werden. Versuchen Sie die folgende Abfrage in der Befehlszeilen-Shell, um diese Tabelle zu erstellen.
>> TABELLE ERSTELLEN, WENN NICHT EXISTIERT Makeup(make_Id int PRIMARY KEY, p_name VARCHAR(100) NOT NULL);
Nachdem wir die Tabelle 'Makeup' erstellt haben, fügen wir ihr einige Datensätze hinzu. Wir werden die unten aufgeführte Abfrage in der Shell ausführen, um dieser Tabelle 10 Datensätze hinzuzufügen.

Wir müssen eine weitere Tabelle mit dem Namen "Benutzer" erstellen, die die Datensätze der Benutzer enthält, die diese Produkte verwenden. Führen Sie die unten angegebene Abfrage in der Shell aus, um diese Tabelle zu erstellen.
>> TABELLE ERSTELLEN, WENN NICHT EXISTS users(user_id int PRIMARY KEY, u_name varchar(100) NOT NULL);
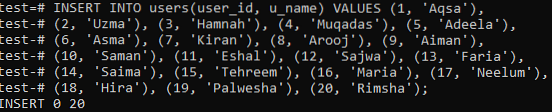
Wir haben die 20 Datensätze für die Tabelle 'Benutzer' eingefügt, wie in der Abbildung unten gezeigt.
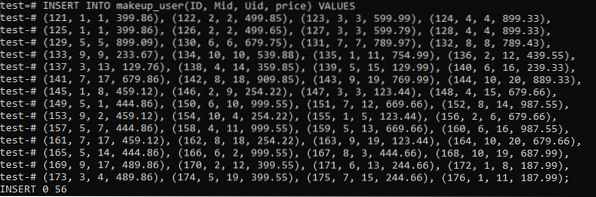
Wir haben eine weitere Tabelle, 'makeup_user', die die gemeinsamen Datensätze der Tabellen 'Makeup' und 'users' enthält. Es hat ein weiteres Feld, 'Preis', das den Preis des Produkts speichert. Die Tabelle wurde mit der unten angegebenen Abfrage erstellt.
>> TABELLE ERSTELLEN, WENN NICHT VORHANDEN Makeup_user( ID int PRIMARY KEY, Mid int NOT NULL REFERENCES Makeup(make_Id), Uid int NOT NULL REFERENCES users(user_id), Preis Dezimal(18,2));
Wir haben insgesamt 56 Datensätze in diese Tabelle eingefügt, wie im Bild gezeigt.
Lassen Sie uns eine weitere Ansicht erstellen, um sie für die Generierung einer Pivot-Tabelle zu verwenden. Diese Ansicht verwendet INNER Join, um die Primärschlüsselspaltenwerte aller drei Tabellen abzugleichen und den "Namen", "Produktname" und die "Kosten" eines Produkts aus einer Tabelle "Kunden" abzurufen
>> ANSICHT ERSTELLEN v_makeup_users AS SELECT c.u_name, p.p_name, pc.Preis VON Benutzern c INNER JOIN Make-up_Benutzer PC ON c.user_id = pc.Uid INNER JOIN Make-up auf dem PC.Mitte = p.make_Id;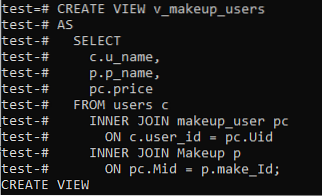
Um dies zu verwenden, müssen Sie zuerst das tablefunc-Paket für die Datenbank installieren, die Sie verwenden möchten. Dieses Paket ist in PostgreSQL 9 integriert.1 und später freigegeben, indem Sie den unten angegebenen Befehl ausführen. Das tablefunc-Paket wurde jetzt für Sie aktiviert.
>> ERWEITERUNG ERSTELLEN, WENN NICHT EXISTS tablefunc;
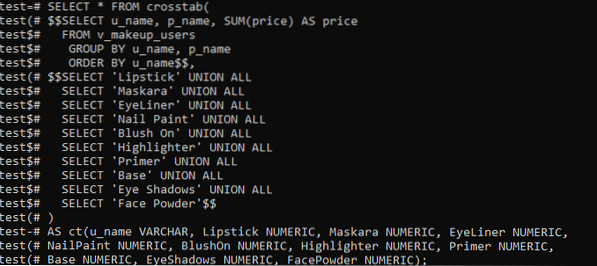
Nach dem Erstellen der Erweiterung ist es an der Zeit, die Funktion Crosstab() zu verwenden, um eine Pivot-Tabelle zu erstellen. Dazu verwenden wir die folgende Abfrage in der Kommandozeilen-Shell. Diese Abfrage ruft zuerst den Datensatz aus der neu erstellten "Ansicht" ab. Diese Datensätze werden in aufsteigender Reihenfolge der Spalten 'u_name' und 'p_name' sortiert und gruppiert. Wir haben ihren Make-up-Namen für jeden Kunden, den sie gekauft haben, und die Gesamtkosten der gekauften Produkte in der Tabelle aufgeführt. Wir haben den Operator UNION ALL auf die Spalte 'p_name' angewendet, um alle von einem Kunden gekauften Produkte separat zusammenzufassen. Dadurch werden alle Kosten der von einem Benutzer gekauften Produkte zu einem Wert zusammengefasst.
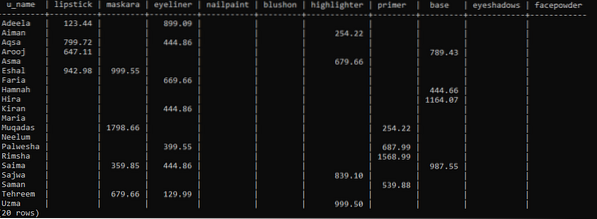
Unsere Pivot-Tabelle ist fertig und wird im Bild angezeigt. Sie können deutlich sehen, dass einige Spaltenräume unter jedem p_name leer sind, weil sie dieses bestimmte Produkt nicht gekauft haben.
Fazit:
Wir haben jetzt brillant gelernt, wie man eine Pivot-Tabelle erstellt, um die Ergebnisse der Tabellen mit und ohne Verwendung des Tablefunc-Pakets zusammenzufassen.


