Warum wird Lucene benötigt?
Die Suche ist eine der häufigsten Operationen, die wir mehrmals täglich durchführen. Diese Suche kann sich über mehrere Webseiten erstrecken, die im Web vorhanden sind, oder eine Musikanwendung oder ein Code-Repository oder eine Kombination aus alledem. Man könnte meinen, dass auch eine einfache relationale Datenbank die Suche unterstützen kann. Das ist richtig. Datenbanken wie MySQL unterstützen die Volltextsuche. Aber was ist mit dem Web oder einer Musikanwendung oder einem Code-Repository oder einer Kombination aus alledem?? Die Datenbank kann diese Daten nicht in ihren Spalten speichern. Selbst wenn dies der Fall wäre, wird es eine inakzeptable Zeit dauern, die Suche so groß zu machen.
Eine Volltextsuchmaschine kann eine Suchanfrage für Millionen von Dateien gleichzeitig ausführen. Die Geschwindigkeit, mit der Daten heute in einer Anwendung gespeichert werden, ist enorm. Die Volltextsuche für diese Art von Datenmenge ist eine schwierige Aufgabe. Dies liegt daran, dass die Informationen, die wir benötigen, in einer einzigen Datei aus Milliarden von Dateien im Internet vorhanden sein können.
So funktioniert Lucene?
Die offensichtliche Frage, die Ihnen in den Sinn kommen sollte, ist, wie schnell Lucene Volltextsuchabfragen durchführt?? Die Antwort darauf ist natürlich mit Hilfe von Indizes, die es erstellt. Aber anstatt einen klassischen Index zu erstellen, verwendet Lucene Invertierte Indizes.
In einem klassischen Index sammeln wir für jedes Dokument die vollständige Liste der Wörter oder Begriffe, die das Dokument enthält. In einem invertierten Index speichern wir für jedes Wort in allen Dokumenten, in welchem Dokument und an welcher Position sich dieses Wort/dieser Begriff befindet. Dies ist ein High-Standard-Algorithmus, der die Suche sehr einfach macht. Betrachten Sie das folgende Beispiel zum Erstellen eines klassischen Index:
Doc1 -> "This", "is", "simple", "Lucene", "sample", "classic", "inverted", "index"Doc2 -> "Läuft", "Elasticsearch", "Ubuntu", "Update"
Doc3 -> "RabbitMQ", "Lucene", "Kafka", "", "Frühling", "Boot"
Wenn wir den invertierten Index verwenden, haben wir Indizes wie:
Dies -> (2, 71)Lucene -> (1, 9), (12,87)
Apache -> (12, 91)
Rahmen -> (32, 11)
Invertierte Indizes sind viel einfacher zu pflegen. Angenommen, wenn wir Apache in meinen Begriffen finden möchten, habe ich sofort Antworten mit invertierten Indizes, während die klassische Suche auf vollständigen Dokumenten ausgeführt wird, die in Echtzeitszenarien möglicherweise nicht ausgeführt werden konnten.
Lucene-Workflow
Bevor Lucene die Daten tatsächlich durchsuchen kann, muss es Schritte ausführen. Lassen Sie uns diese Schritte zum besseren Verständnis visualisieren:
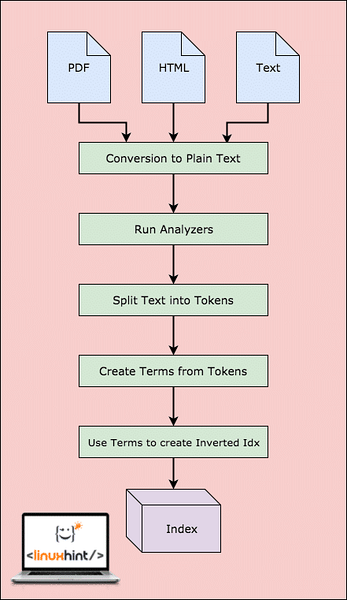
Lucene-Workflow
Wie im Diagramm gezeigt, passiert in Lucene Folgendes:
- Lucene wird mit den Dokumenten und anderen Datenquellen gefüttert
- Für jedes Dokument wandelt Lucene diese Daten zuerst in Klartext um und dann konvertiert der Analyzer diese Quelle in Klartext
- Für jeden Begriff im Klartext werden die invertierten Indizes erstellt
- Die Indizes können durchsucht werden
Mit diesem Workflow ist Lucene eine sehr starke Volltextsuchmaschine. Aber das ist der einzige Teil, den Lucene erfüllt. Wir müssen die Arbeit selbst ausführen. Schauen wir uns die benötigten Komponenten der Indexierung an.
Lucene-Komponenten
In diesem Abschnitt beschreiben wir die grundlegenden Komponenten und die grundlegenden Lucene-Klassen, die zum Erstellen von Indizes verwendet werden:
- Verzeichnisse: Ein Lucene-Index speichert Daten in normalen Dateisystemverzeichnissen oder im Speicher, wenn Sie mehr Leistung benötigen. Es ist völlig die Wahl der Apps, um Daten zu speichern, wo immer sie wollen, eine Datenbank, den RAM oder die Festplatte.
- Unterlagen: Die Daten, die wir in die Lucene-Engine einspeisen, müssen in Klartext konvertiert werden. Dazu erstellen wir ein Document-Objekt, das diese Datenquelle darstellt. Wenn wir später eine Suchabfrage ausführen, erhalten wir als Ergebnis eine Liste von Document-Objekten, die die von uns übergebene Abfrage erfüllen satisfy.
- Felder: Dokumente werden mit einer Sammlung von Feldern gefüllt. Ein Feld ist einfach ein Paar von (Name, Wert) Artikel. Wenn wir also ein neues Document-Objekt erstellen, müssen wir es mit dieser Art von gepaarten Daten füllen. Wenn ein Feld invertiert indiziert ist, wird der Wert des Felds tokenisiert und ist für die Suche verfügbar. Während wir nun Felder verwenden, ist es nicht wichtig, das tatsächliche Paar zu speichern, sondern nur das invertierte indizierte. Auf diese Weise können wir entscheiden, welche Daten nur durchsuchbar und nicht wichtig für die Speicherung sind. Schauen wir uns hier ein Beispiel an:

Feldindizierung
In der obigen Tabelle haben wir uns entschieden, einige Felder zu speichern und andere werden nicht gespeichert. Das Body-Feld wird nicht gespeichert, sondern indiziert. Dies bedeutet, dass die E-Mail als Ergebnis zurückgegeben wird, wenn die Abfrage nach einem der Begriffe für den Nachrichtentext ausgeführt wird.
- Bedingungen: Begriffe repräsentiert ein Wort aus dem Text. Terme werden aus der Analyse und Tokenisierung der Werte von Feldern extrahiert, also Begriff ist die kleinste Einheit, nach der gesucht wird.
- Analysatoren: Ein Analyzer ist der wichtigste Teil des Indexierungs- und Suchprozesses. Es ist der Analyzer, der den Klartext in Token und Begriffe umwandelt, damit sie durchsucht werden können. Nun, das ist nicht die einzige Verantwortung eines Analysators. Ein Analyzer verwendet einen Tokenizer, um Token zu erstellen. Ein Analysator führt auch die folgenden Aufgaben aus:
- Stammbaum: Ein Analysator wandelt das Wort in einen Stamm um. Das bedeutet, dass 'Blumen' in das Stammwort 'Blume' umgewandelt wird. Wenn also nach 'Blume' gesucht wird, wird das Dokument zurückgegeben.
- Filtern: Ein Analyzer filtert auch die Stoppwörter wie 'The', 'is' etc. da diese Wörter keine Abfragen anziehen und nicht produktiv sind.
- Normalisierung: Dieser Vorgang entfernt Akzente und andere Zeichenmarkierungen.
Dies ist nur die normale Verantwortung von StandardAnalyzer.
Beispielanwendung
Wir werden einen der vielen Maven-Archetypen verwenden, um ein Beispielprojekt für unser Beispiel zu erstellen. Um das Projekt zu erstellen, führen Sie den folgenden Befehl in einem Verzeichnis aus, das Sie als Arbeitsbereich verwenden:
mvn archetype:generate -DgroupId=com.linuxhint.example -DartifactId=LH-LuceneExample -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=falseWenn Sie Maven zum ersten Mal ausführen, dauert es einige Sekunden, bis der Befehl "Generieren" ausgeführt wird, da Maven alle erforderlichen Plugins und Artefakte herunterladen muss, um die Generierungsaufgabe auszuführen. So sieht die Projektausgabe aus:
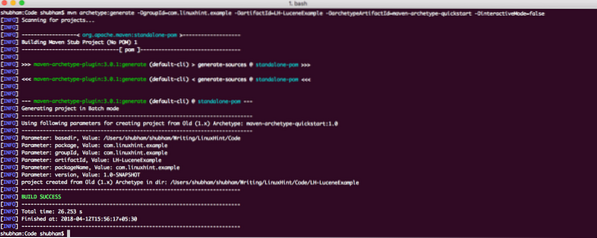
Projektaufbau
Sobald Sie das Projekt erstellt haben, können Sie es in Ihrer bevorzugten IDE öffnen. Der nächste Schritt besteht darin, dem Projekt entsprechende Maven-Abhängigkeiten hinzuzufügen. Hier ist die Pom.xml-Datei mit den entsprechenden Abhängigkeiten:
Um schließlich alle JARs zu verstehen, die dem Projekt hinzugefügt werden, wenn wir diese Abhängigkeit hinzugefügt haben, können wir einen einfachen Maven-Befehl ausführen, der es uns ermöglicht, einen vollständigen Abhängigkeitsbaum für ein Projekt anzuzeigen, wenn wir einige Abhängigkeiten hinzufügen. Hier ist ein Befehl, den wir verwenden können:
mvn-Abhängigkeit: BaumWenn wir diesen Befehl ausführen, wird uns der folgende Abhängigkeitsbaum angezeigt: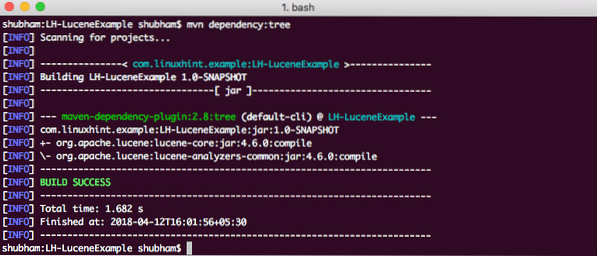
Schließlich erstellen wir eine SimpleIndexer-Klasse, die ausgeführt wird
Java importieren.io.Datei;
Java importieren.io.FileReader;
Java importieren.io.IOAusnahme;
Importorganisation.Apache.lucene.Analyse.Analysator;
Importorganisation.Apache.lucene.Analyse.Standard.StandardAnalyzer;
Importorganisation.Apache.lucene.Dokument.Dokument;
Importorganisation.Apache.lucene.Dokument.Gespeichertes Feld;
Importorganisation.Apache.lucene.Dokument.Textfeld;
Importorganisation.Apache.lucene.Index.IndexWriter;
Importorganisation.Apache.lucene.Index.IndexWriterConfig;
Importorganisation.Apache.lucene.Geschäft.FSVerzeichnis;
Importorganisation.Apache.lucene.util.Ausführung;
öffentliche Klasse SimpleIndexer
private static final String indexDirectory = "/Users/shubham/somewhere/LH-LuceneExample/Index";
private static final String dirToBeIndexed = "/Users/shubham/somewhere/LH-LuceneExample/src/main/java/com/linuxhint/example";
public static void main(String[] args) wirft Ausnahme
Datei indexDir = new File(indexDirectory);
Datei dataDir = new File(dirToBeIndexed);
SimpleIndexer-Indexer = neuer SimpleIndexer();
int numIndexed = indexer.index(indexDir, dataDir);
System.aus.println("Indizierte Dateien insgesamt" + numIndexed);
private int index(File indexDir, File dataDir) wirft IOException
Analyzer Analyzer = neuer StandardAnalyzer(Versionzer.LUCENE_46);
IndexWriterConfig config = neue IndexWriterConfig(Version.LUCENE_46,
Analysator);
IndexWriter indexWriter = new IndexWriter(FSDirectory.open(indexDir),
konfigurieren);
File[] files = dataDir.listFiles();
für (Datei f: Dateien)
System.aus.println("Datei indexieren" + f.getCanonicalPath());
Dokumentdokument = neues Dokument();
doc.add(new TextField("content", new FileReader(f)));
doc.add(new StoredField("fileName", f.getCanonicalPath()));
indexWriter.addDocument(doc);
int numIndexed = indexWriter.maxDoc();
indexWriter.schließen();
Return numIndexed;
In diesem Code haben wir gerade eine Document-Instanz erstellt und ein neues Feld hinzugefügt, das den Dateiinhalt darstellt. Hier ist die Ausgabe, die wir erhalten, wenn wir diese Datei ausführen:
Indexierungsdatei /Users/shubham/somewhere/LH-LuceneExample/src/main/java/com/linuxhint/example/SimpleIndexer.JavaGesamtzahl der indizierten Dateien 1
Außerdem wird innerhalb des Projekts ein neues Verzeichnis mit folgendem Inhalt erstellt:
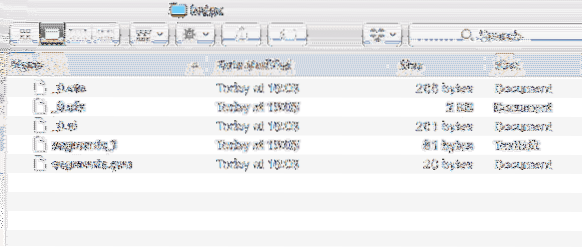
Indexdaten
Wir werden in weiteren Lektionen auf Lucene analysieren, welche Dateien in diesem Index erstellt werden.
Fazit
In dieser Lektion haben wir uns die Funktionsweise von Apache Lucene angesehen und eine einfache Beispielanwendung erstellt, die auf Maven und Java basiert.


