In diesem Artikel zeige ich Ihnen, wie Sie mit Selenium die aktuelle URL des Browsers abrufen. Also lasst uns anfangen.
Voraussetzungen:
Um die Befehle und Beispiele dieses Artikels auszuprobieren, müssen Sie,
1) Eine auf Ihrem Computer installierte Linux-Distribution (vorzugsweise Ubuntu).
2) Python 3 auf Ihrem Computer installiert.
3) PIP 3 auf Ihrem Computer installiert.
4) Python virtuelle Umgebung Paket auf Ihrem Computer installiert.
5) Mozilla Firefox- oder Google Chrome-Webbrowser, die auf Ihrem Computer installiert sind.
6) Muss wissen, wie man den Firefox Gecko-Treiber oder den Chrome Web-Treiber installiert install.
Um die Anforderungen 4, 5 und 6 zu erfüllen, lesen Sie bitte meinen Artikel Einführung in Selenium mit Python 3 bei Linuxhint.com.
Viele Artikel zu den anderen Themen finden Sie auf LinuxHint.com. Schauen Sie sie sich an, wenn Sie Hilfe benötigen.
Einrichten eines Projektverzeichnisses:
Um alles organisiert zu halten, erstellen Sie ein neues Projektverzeichnis Selen-URL/ wie folgt:
$ mkdir -pv selenium-url/drivers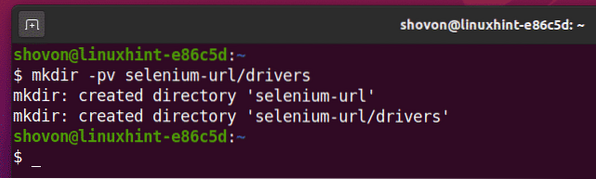
Navigieren Sie zum Selen-URL/ Projektverzeichnis wie folgt:
$ cd selen-url/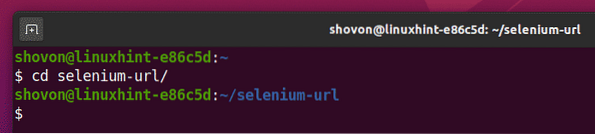
Erstellen Sie eine virtuelle Python-Umgebung im Projektverzeichnis wie folgt:
$ virtualenv .venv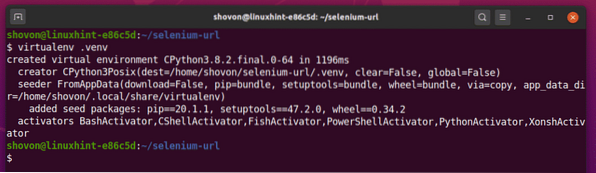
Aktivieren Sie die virtuelle Umgebung wie folgt:
$ Quelle .venv/bin/aktivieren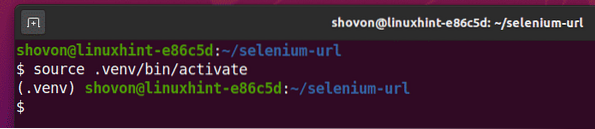
Installieren Sie die Selenium Python-Bibliothek in Ihrer virtuellen Umgebung mit PIP3 wie folgt:
$ pip3 Selen installieren
Laden Sie alle erforderlichen Webtreiber im herunter und installieren Sie sie Fahrer/ Verzeichnis des Projekts. Den Vorgang zum Herunterladen und Installieren von Webtreibern habe ich in meinem Artikel erklärt Einführung in Selenium mit Python 3. Wenn Sie Hilfe benötigen, suchen Sie auf LinuxHinweis.com für diesen Artikel.
Ich werde den Google Chrome-Webbrowser für die Demonstration in diesem Artikel verwenden. Also werde ich die verwenden Chromtreiber binär mit Selen. Sie sollten die verwenden Geckotreiber binär, wenn Sie den Firefox-Webbrowser verwenden möchten.
Aktuelle URL mit Selenium abrufen:
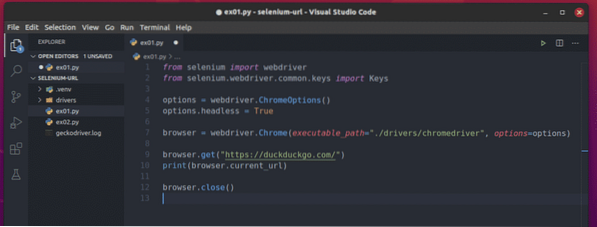
Erstellen Sie ein Python-Skript ex01.py in Ihrem Projektverzeichnis und geben Sie die folgenden Codezeilen ein.
vom Selen-Import-Webtreiberaus Selen.Webtreiber.verbreitet.Schlüsselimport Schlüssel
Optionen = Webtreiber.ChromeOptions()
Optionen.kopflos = wahr
Browser = Webtreiber.Chrome(executable_path="./drivers/chromedriver", options=options)
Browser.get("https://duckduckgo.com/")
drucken (Browser.aktuelle_URL)
Browser.schließen()
Wenn Sie fertig sind, speichern Sie die ex01.py Python-Skript.
Hier importieren Zeile 1 und Zeile 2 alle benötigten Komponenten aus der Python-Selen-Bibliothek.

Zeile 4 erstellt ein Chrome-Optionsobjekt und Zeile 5 aktiviert den Headless-Modus für den Chrome-Webbrowser.

Zeile 7 erstellt ein Chrome Browser Objekt mit dem Chromtreiber binär aus dem Fahrer/ Verzeichnis des Projekts.

Zeile 9 weist den Browser an, das duckduckgo zu laden.com-Website.

Zeile 10 gibt die aktuelle URL des Browsers aus. Hier, Browser.aktuelle_url -Eigenschaft wird verwendet, um auf die aktuelle URL des Browsers zuzugreifen.

Zeile 12 schließt den Browser.

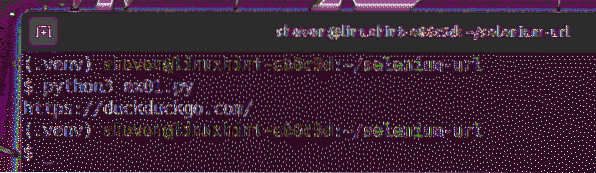
Führen Sie das Python-Skript aus ex01.py wie folgt:
$ python3 ex01.py
Wie Sie sehen, ist die aktuelle URL (https://duckduckgo.com) wird auf der Konsole gedruckt.
Im vorherigen Beispiel habe ich die Website duckduckgo . besucht.com und druckte die aktuelle URL auf der Konsole. Dies gibt die URL der Seite zurück, die wir besuchen. Nicht sehr schick, da wir die Seiten-URL bereits kennen. Lassen Sie uns nun auf DuckDuckGo nach etwas suchen und versuchen, die URL der Suchergebnisseite auf der Konsole zu drucken.
Erstellen Sie ein Python-Skript ex02.py in Ihrem Projektverzeichnis und geben Sie die folgenden Codezeilen ein.
vom Selen-Import-Webtreiberaus Selen.Webtreiber.verbreitet.Schlüsselimport Schlüssel
Optionen = Webtreiber.ChromeOptions()
Optionen.kopflos = wahr
Browser = Webtreiber.Chrome(executable_path="./drivers/chromedriver", options=options)
Browser.get("https://duckduckgo.com/")
drucken (Browser.aktuelle_URL)
searchInput = Browser.find_element_by_id('search_form_input_homepage')
SucheInput.send_keys('Selen-Hauptquartier' + Schlüssel.EINGEBEN)
drucken (Browser.aktuelle_URL)
Browser.schließen()
Wenn Sie fertig sind, speichern Sie die ex02.py Python-Skript.
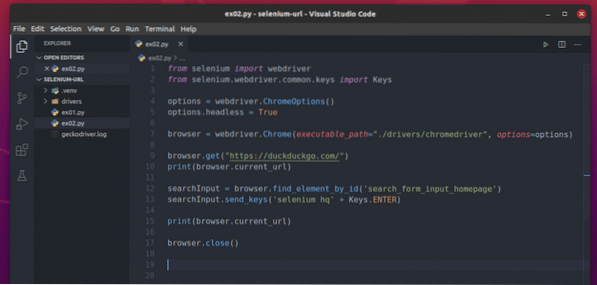
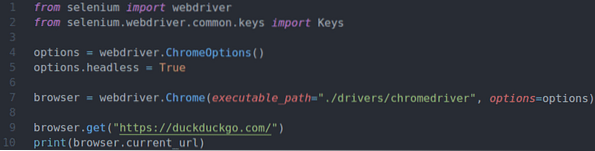
Hier sind die Zeilen 1-10 die gleichen wie in ex01.py. Also erkläre ich sie nicht noch einmal.
Zeile 12 findet das Suchtextfeld und speichert es im SucheInput Variable.
Zeile 13 sendet die Suchanfrage Selen hq in dem SucheInput Textfeld und drückt die

Sobald die Suchseite geladen ist, Browser.aktuelle_url wird verwendet, um auf die aktualisierte aktuelle URL zuzugreifen.
Zeile 15 gibt die aktualisierte aktuelle URL auf der Konsole aus.

Zeile 17 schließt den Browser.

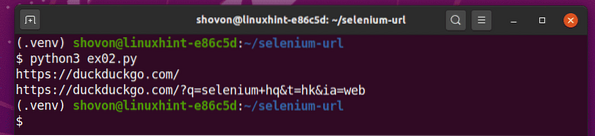
Führen Sie die ex02.py Python-Skript wie folgt:
$ python3 ex02.py
Wie Sie sehen können, ist das Python-Skript ex02.py druckt 2 URLs.
Die erste ist die Homepage-URL der DuckDuckGo-Suchmaschine.
Die zweite ist die aktualisierte aktuelle URL nach einer Suche in der DuckDuckGo-Suchmaschine mit der Abfrage Selen hq.
Fazit:
In diesem Artikel habe ich Ihnen gezeigt, wie Sie die aktuelle URL des Webbrowsers mithilfe der Selenium-Python-Bibliothek abrufen. Jetzt sollten Sie in der Lage sein, Ihre Selenium-Projekte interessanter zu gestalten.


