Syntax
Grep [Muster] [Dateiname]
Nach der Verwendung von grep kommt ein Muster. Das Muster impliziert die Art und Weise, wie wir es verwenden möchten, um zusätzlichen Platz in den Daten zu entfernen. Nach dem Muster wird der Dateiname beschrieben, durch den das Muster ausgeführt wird.
Voraussetzung
Um die Nützlichkeit von grep leicht zu verstehen, müssen wir Ubuntu auf unserem System installiert haben. Geben Sie Benutzerdetails an, indem Sie Benutzernamen und Kennwort angeben, um Berechtigungen für den Zugriff auf die Anwendungen von Linux zu haben. Öffnen Sie nach der Anmeldung die Anwendung und suchen Sie nach einem Terminal oder wenden Sie die Tastenkombination Strg+Alt+T . an.
Durch Verwendung des Schlüsselworts [: blank:]
Angenommen, wir haben eine Datei namens bfile mit einer Texterweiterung. Sie können eine Datei entweder im Texteditor oder mit einer Befehlszeile im Terminal erstellen. So erstellen Sie eine Datei auf dem Terminal, einschließlich der folgenden Befehle.
$ Echo „in eine Datei einzugebender Text“ > Dateiname.TXTEs ist nicht erforderlich, eine Datei zu erstellen, wenn sie bereits vorhanden ist. Zeigen Sie es einfach mit dem angehängten Befehl an:
$ echo Dateiname.TXTText, der in diese Dateien geschrieben wird, enthält Leerzeichen zwischen ihnen, wie in der Abbildung unten gezeigt.
![]()
Diese Leerzeilen können mit einem Leerbefehl entfernt werden, um Leerzeichen zwischen den Wörtern oder Zeichenfolgen zu ignorieren.
$ egrep '^[[:leer]]*[^[:leer:]#]' bfile.TXT![]()
Nach dem Anwenden der Abfrage werden die Leerzeichen zwischen den Zeilen entfernt und die Ausgabe enthält keine zusätzlichen Leerzeichen mehr. Das erste Wort wird hervorgehoben, da Leerzeichen zwischen dem letzten Wort der Zeile und zwischen den ersten Wörtern der nächsten Zeile entfernt werden. Wir können auch Bedingungen auf denselben grep-Befehl anwenden, indem wir diese leere Funktion hinzufügen, um unnötigen Platz in der Ausgabe zu entfernen.
Durch Verwenden von [: Leerzeichen:]
Ein weiteres Beispiel für das Ignorieren von Leerzeichen wird hier erklärt.
Ohne die Dateierweiterung zu erwähnen, werden wir zuerst die vorhandene Datei mit dem Befehl anzeigen.
$ Katzendatei20![]()
Sehen wir uns an, wie zusätzlicher Speicherplatz mit dem Befehl grep neben dem Schlüsselwort [:space:] entfernt wird. Die Option -v von Grep hilft beim Drucken von Zeilen, denen Leerzeilen und zusätzliche Abstände fehlen, die auch in einem Absatzformular enthalten sind.
$ grep -v '^[[;Leerzeichen:]]*$' Datei20Sie werden sehen, dass zusätzliche Zeilen entfernt werden und die Ausgabe zeilenweise in sequenzierter Form erfolgt. So ist die grep -v-Methodik so hilfreich, um das erforderliche Ziel zu erreichen.
![]()
Das Erwähnen von Dateierweiterungen schränkt die grep-Funktionalität so ein, dass sie nur für die bestimmten Dateierweiterungen ausgeführt wird, d. h.e., .Text oder .mp3. Wenn wir eine Ausrichtung an einer Textdatei durchführen, nehmen wir fileg.txt als Beispieldatei. Zuerst werden wir den darin enthaltenen Text mit der Funktion $ cat anzeigen. Ausgabe ist wie folgt:
![]()
Durch Anwenden des Befehls wurde unsere Ausgabedatei erhalten. Hier sehen wir Daten ohne Abstand zwischen den Zeilen, die nacheinander geschrieben werden.
$ grep -v '^[[:Leerzeichen:]]*$' Dateig.TXT![]()
Neben langen Befehlen können wir auch mit den kurzen geschriebenen Befehlen in Linux und Unix arbeiten, um zu implementieren, dass grep darin Kurzzeichen unterstützt.
$ grep '\s' Dateiname.TXTWir haben gesehen, wie die Ausgabe durch Anwenden von Befehlen aus der Eingabe erhalten wird. Hier erfahren wir, wie die Eingabe von der Ausgabe zurückgehalten wird.
$ grep '\S' Dateiname.txt > tmp.txt && mv tmp.txt-Dateiname.TXTHier verwenden wir eine temporäre Textdatei mit der Texterweiterung tmp.
Mit ^#
Genau wie in anderen beschriebenen Beispielen werden wir den Befehl mit dem Befehl cat auf die Textdatei anwenden. Wir können auch Text mit dem echo-Befehl anzeigen.
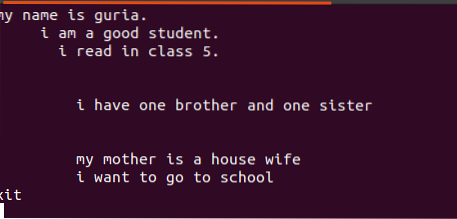
$ echo Dateiname.TXTDie Textdatei enthält 4 Zeilen mit Leerzeichen dazwischen. Diese Leerzeichen lassen sich leicht mit einem bestimmten Befehl entfernen.
![]()
Reguläre erweiterte Operationen werden durch -E aktiviert, was alle regulären Ausdrücke erlaubt, insbesondere Pipe. Ein Rohr wird in jedem Muster als optionale „oder“-Bedingung verwendet.”^#”. Dies zeigt die Übereinstimmung von Textzeilen in der Datei, die mit dem Zeichen # beginnt. „^$“ wird mit allen freien Leerzeichen im Text oder Leerzeilen übereinstimmen.
![]()
Die Ausgabe zeigt die vollständige Entfernung von zusätzlichem Leerzeichen zwischen den Zeilen in der Datendatei lines. In diesem Beispiel haben wir gesehen, dass im Befehl ”^#” zuerst kommt, was bedeutet, dass der Text zuerst abgeglichen wird. „^$“ kommt nach | Operator, also wird der freie Speicherplatz danach abgeglichen.
Mit ^$
Genau wie im oben genannten Beispiel werden wir zu den gleichen Ergebnissen kommen, da der Befehl fast gleich ist. Das Muster ist jedoch umgekehrt geschrieben. Datei22.txt ist eine Datei, die wir zum Entfernen von Leerzeichen verwenden werden.
![]()
Es wird dieselbe Methodik angewendet, mit Ausnahme des Arbeitens mit Priorität. Gemäß diesem Befehl werden zuerst freie Plätze abgeglichen, dann werden die Textdateien abgeglichen. Die Ausgabe liefert eine Folge von Zeilen, indem zusätzliche Lücken darin entfernt werden.
![]()
Andere einfache Befehle
- Grep '^…' Dateiname.
- Grep '.' Dateiname
Beides ist so einfach und hilft beim Entfernen von Lücken in Textzeilen.
Fazit
Das Entfernen unnötiger Lücken in Dateien mit Hilfe von regulären Ausdrücken ist ein recht einfacher Ansatz, um eine reibungslose Datenfolge zu erreichen und die Konsistenz zu wahren. Beispiele werden ausführlich erklärt, um Ihre Informationen zum Thema zu verbessern.


