Syntax
$ grep 'Muster1\|Muster2' DateinameEin regulärer Ausdruck wird immer in einem einfachen Anführungszeichen geschrieben. Zwei Namen werden mit Backslash und Änderungsoperator getrennt. Der Befehl wird mit dem Dateinamen beendet. Bei grep rekursiv wird das Verzeichnis oder der ganze Pfad anstelle eines einzelnen Dateinamens verwendet.
Voraussetzung
In diesem Artikel lernen wir die Funktionalität von grep bei der Suche nach mehreren Mustern und Strings kennen. Dazu muss das Linux-Betriebssystem auf Ihrer virtuellen Box laufen. Sie müssen es auf Ihrem System installieren. Nach der Konfiguration haben Sie Zugriff auf alle Anwendungen. Nachdem Sie sich durch Eingabe eines Passworts beim Benutzer angemeldet haben, gehen Sie zur Terminal-Shell-Befehlszeile, um fortzufahren.
Suche nach mehreren Mustern in einer Datei mit Grep
Wenn wir in einer bestimmten Datei nach mehreren Mustern oder Zeichenfolgen suchen möchten, verwenden Sie die grep-Funktionalität, um innerhalb einer Datei mit Hilfe von mehr als einem Eingabewort im Befehl zu sortieren. Wir verwenden '\|' Operatoren zur Trennung zweier Muster in einem Befehl.
$ grep 'technical\|job'-Dateia.TXTDer Befehl stellt dar, wie grep funktioniert. Beide genannten Dateien werden in filea . durchsucht.TXT. Gesuchte Wörter werden im gesamten Text der Ausgabe hervorgehoben.

Um nach mehr als zwei Wörtern zu suchen, fügen wir sie auf die gleiche Weise hinzu.
$ grep 'graphic\|photoshop\|posters' fileb.TXT
Durchsuchen Sie mehrere Zeichenfolgen, indem Sie die Groß-/Kleinschreibung ignorieren
Um das Konzept der Groß-/Kleinschreibung in der grep-Funktion in Linux zu verstehen, betrachten Sie das folgende Beispiel. Zwei Befehle funktionieren auf grep. Einer ist mit '-i' und der andere ist ohne. Dieses Beispiel demonstriert die Unterschiede zwischen den Befehlen. Das erste zeigt an, dass in einer bestimmten Datei nach zwei Wörtern gesucht wird. Es beginnt jedoch, wie im Befehl „Aqsa“ angegeben, mit dem Großbuchstaben A. Daher wird er nicht hervorgehoben, da dieser Text in einer bestimmten Datei in Kleinbuchstaben geschrieben ist.
$ grep 'Aqsa\|Schwester'-Datei20.TXTEs wird nur das Wort Schwester berücksichtigt, das in der Ausgabe zu sehen ist.
Im zweiten Beispiel haben wir die Groß-/Kleinschreibung ignoriert, indem wir das Flag „-I“ verwendet haben. Diese Funktion sucht nach beiden Wörtern und die Ausgabe wird hervorgehoben. Unabhängig davon, ob das Wort 'Aqsa' in Großbuchstaben geschrieben ist oder nicht, grep sucht nach derselben Übereinstimmung im Text in einer Datei. Beide Befehle sind also auf ihre Weise hilfreich.
$ grep -I 'Aqsa\|Schwester'-Datei20.TXT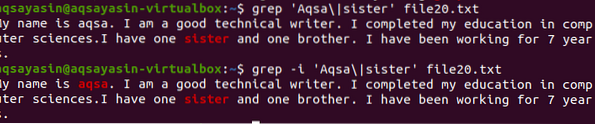
Zählen mehrerer Übereinstimmungen in einer Datei
Die Zählfunktion hilft beim Zählen des Vorkommens eines Wortes oder von Wörtern in einer bestimmten Datei. Wenn Sie zum Beispiel wissen möchten, welche Fehler im System auftreten. Das Detail wird in der Protokolldatei aufgezeichnet. Um diese Informationen in einem bestimmten Ordner zu verwalten, schreiben Sie den Pfad der Ordner. Dieses Beispiel zeigt, dass 71 Fehler in Protokolldateien aufgetreten sind.

Genaue Übereinstimmungen in einer Datei suchen
Wenn Sie eine genaue Übereinstimmung in den Dateien Ihres Systems finden möchten, müssen Sie das Flag „-w“ verwenden, um es genau zu sortieren. Wir haben ein einfaches und umfassendes Beispiel zitiert. Betrachten Sie im folgenden Beispiel eine Suche ohne „-w“, dieser Befehl bringt beide Wörter als Übereinstimmung mit der angegebenen Eingabe. Aber mit der Verwendung des Flags „-w“ wird die Suche eingeschränkt, da die Eingabewörter nur mit der ersten Zeichenfolge übereinstimmen. Das zweite Wort wird nicht hervorgehoben, da „-w“ eine genaue Übereinstimmung mit dem Muster ermöglicht.
$ -iw 'hamna\|house'-Datei21.TXTHier wird -I auch verwendet, um die Groß-/Kleinschreibung bei der Textsuche zu entfernen.

Wie auf dem Foto zu sehen, sind die Ergebnisse nicht die gleichen. Der erste Befehl bringt alle zugehörigen Daten mit ganzen Strings, während der zweite Befehl zeigt, wie genaue Daten durch grep bei der Suche nach mehreren Strings übereinstimmen.
Grep für mehr als ein Muster in einem bestimmten Dateierweiterungstyp
Die Suche erfolgt in allen Dateien. Es liegt an Ihnen, wenn Sie nach dem Dateinamen suchen. Es wird nur in bestimmten Dateien gesucht. Durch die Angabe einer Dateierweiterung werden die Daten jedoch in allen Dateien mit derselben Erweiterung durchsucht. Es gibt zwei verschiedene Beispiele, um das zugehörige Ergebnis darzustellen. Betrachtet man das erste Beispiel, werden Fehlerdateien in allen Dateien des .Log-Erweiterung. „-c“ wird zum Zählen verwendet.
$ grep -c 'Warnung\|Fehler' /var/log/*.Log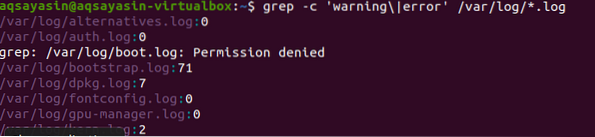
Dieser Befehl impliziert, dass die Dateien in allen Dateien des .Log-Erweiterung. Die Anzahl der Übereinstimmungen wird in der Ausgabe angezeigt, um grep mit der spezifischen Dateierweiterung besser zu demonstrieren.
Im zweiten Beispiel haben wir in unseren Linux-Dateien zwei Wörter mit der Erweiterung des Textes verwendet. Alle Daten werden in Form von Zahlen angezeigt. 0 zeigt keine übereinstimmenden Daten an, während andere als 0 anzeigen, dass eine Übereinstimmung existiert.
$ grep -c 'aqsa\|my' /home/aqsayasin/*.TXT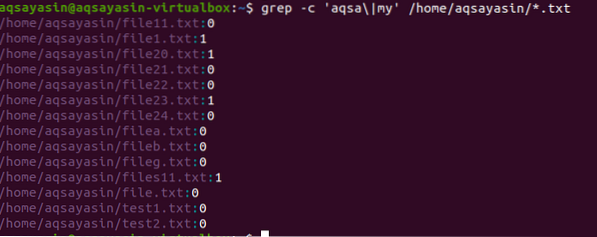
Mehrere Muster rekursiv in einer Datei durchsuchen
Standardmäßig wird das aktuelle Verzeichnis verwendet, wenn im Befehl kein Verzeichnis erwähnt wird. Wenn Sie im Verzeichnis Ihrer Wahl suchen möchten, dann müssen Sie dies erwähnen. Der Operator „-r“ wird rekursiv für grep verwendet./home/aqsayasin/ zeigt den Dateipfad an, während *.txt zeigt die Erweiterung an. Textdateien werden das Ziel von grep sein, um rekursiv zu suchen.
$ grep -R 'technisch\|kostenlos' /home/aqsayasin/*.TXT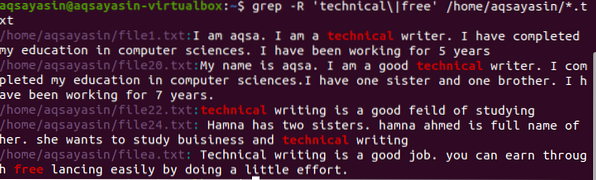
Die gewünschte Ausgabe wird im Ergebnis hervorgehoben und zeigt die Existenz dieser Wörter an.
Fazit
In dem oben erwähnten Artikel haben wir verschiedene Beispiele zitiert, um es einem Benutzer zu erleichtern, die Funktionsweise von Befehlen zum Durchsuchen mehrerer Muster unter Linux zu verstehen. Dieser Leitfaden hilft Ihnen, Ihr vorhandenes Wissen zu erweitern.

